如何在SPSS中进行快速聚类分析?许多用户在使用SPSS数据分析软件时会遇到一些问题。最近,许多朋友问SPS如何快速聚类分析。让我们向您解释一下!
操作方法:
方法概述
聚类分析是一种按照一定标准对研究对象进行分类的方法。分类结果是每组对象相似度高,组间对象差异大。
这种分析方法主要用于对数据样本没有具体分类依据的情况,IBM SPSS Statistics 用户将通过观察数据进行更完美的分类。
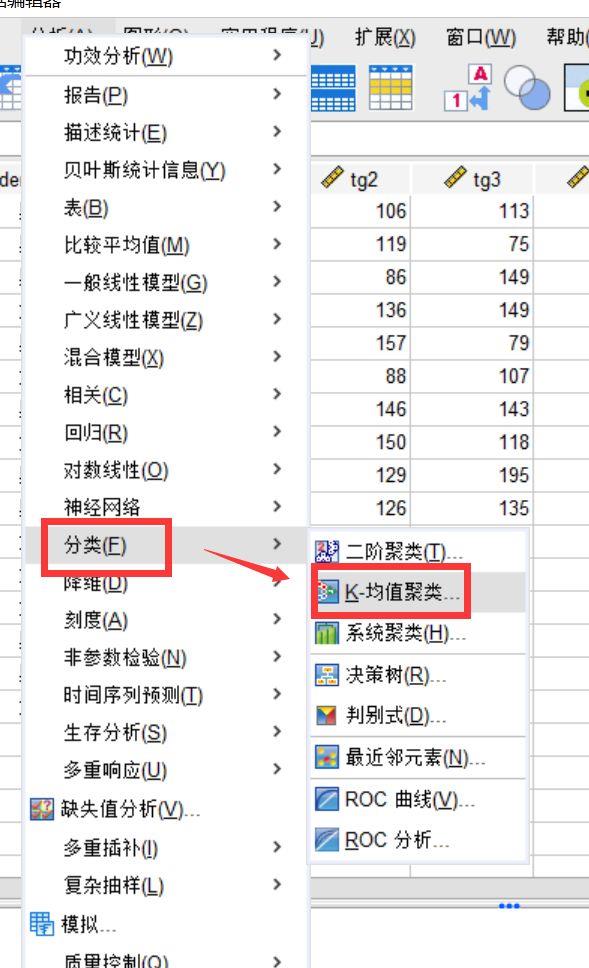) 图1:功能位置
图1:功能位置
快速聚类是聚类分析中使用的一种功能“分析”——“分类”中的“K-均值聚类”。
案例分享
1、样本数据
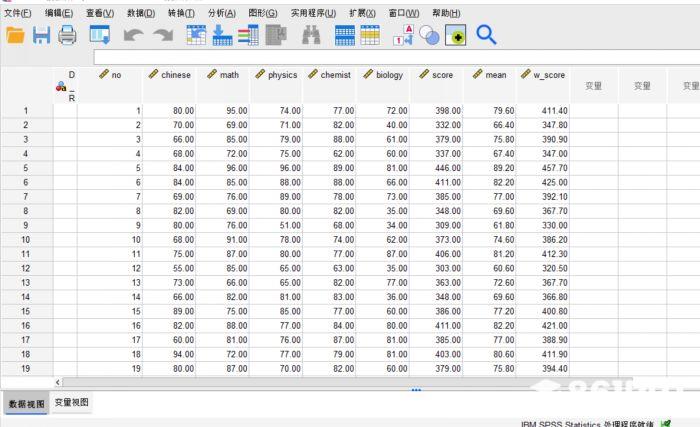) 图2:样本数据
图2:样本数据
我们在这里选择的数据样本是一些学生的期末成绩。快速聚类可以分析每个学生成绩分布的差异和共性。
2、变量设置
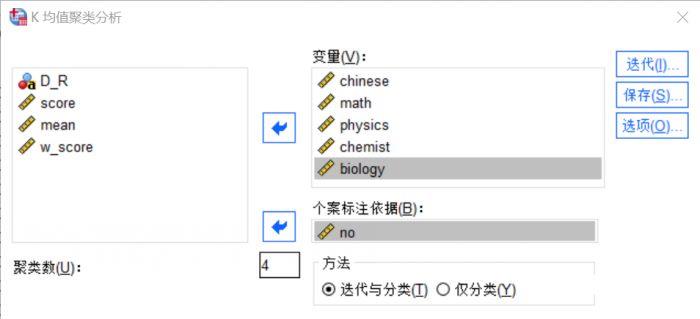) 图3:变量设置
图3:变量设置
我们将学生的所有单科成绩作为分析变量,转移到“变量”在窗口中,将学生的编号变量移动到下面“案例标记依据”窗口。
聚类数设置为分类数,需要根据数据样本的特点设置,我们在这里设置为4类。
聚类方法有两种,即迭代和分类。前者比较复杂,在分析过程中会不断移动凝聚点,而后者总是使用初始凝聚点。我们选择了两种类型的第一种分析方法。
3、聚类中心
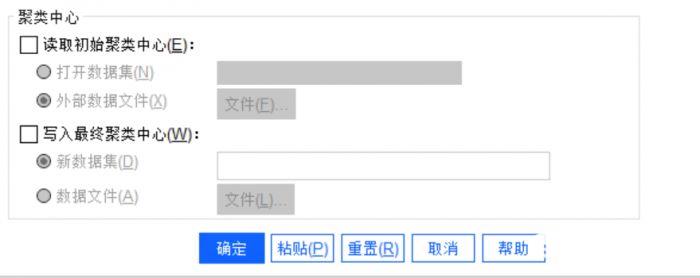) 图4:聚类中心
图4:聚类中心
用户可以选择从外部文件或数据文件中写入或读取聚类中心,我们不使用此功能。
4、迭代设置
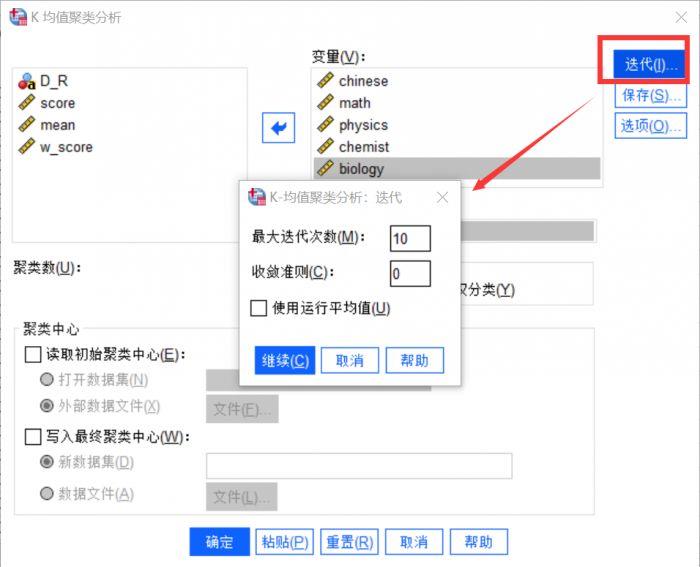) 图5:迭代设置
图5:迭代设置
我们可以设置迭代的终止条件,即在达到设定的最大值后停止迭代分析,并输出聚类分析结果。
收敛标准设置了凝聚点变化的最大距离小于初始凝聚点的比例。当小于设定值时,迭代和输出结果将停止。
使用运行平均值意味着每次观察后重新计算凝聚点,这些设置可以保持默认。
5、保存
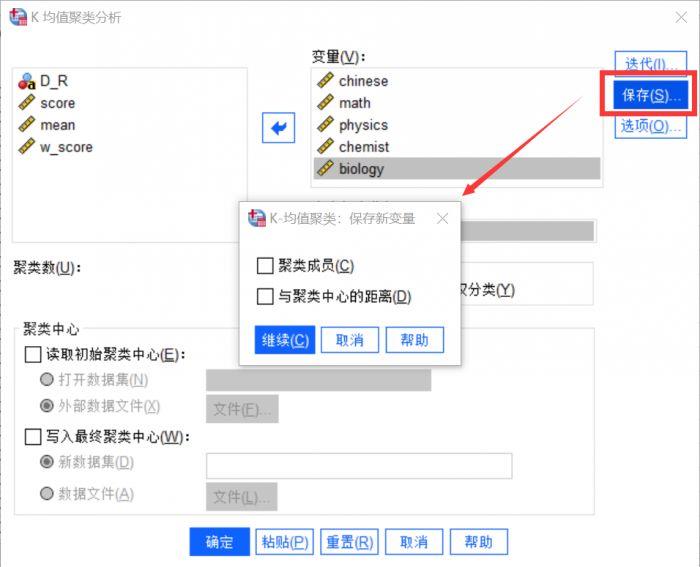) 图6:保存新变量
图6:保存新变量
这是用来设置存储形式和检查的“聚类成员”检查保存SPSS的分类结果“距离聚类中心”我们不设置观测值与所属类别之间的欧氏距离。
6、选项
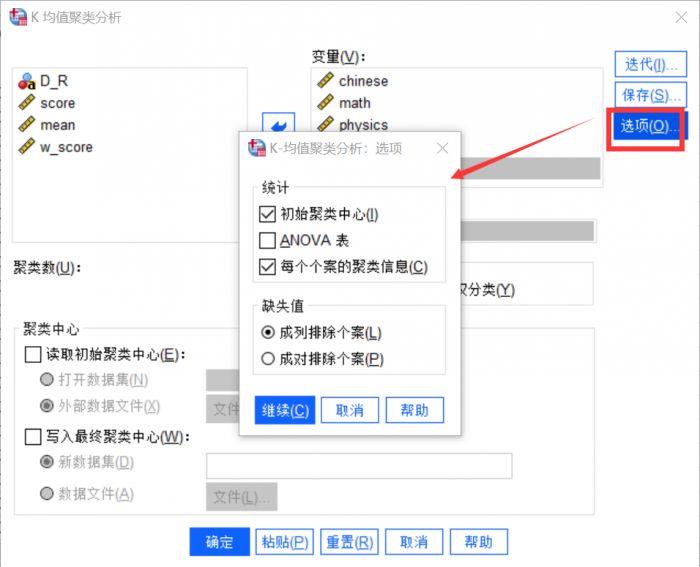) 图7:选项设置
图7:选项设置
该对话框设置了输出统计量和个案缺失处理方法,检查“初始聚类中心”和“每个案例的聚类信息”。
7、结果输出
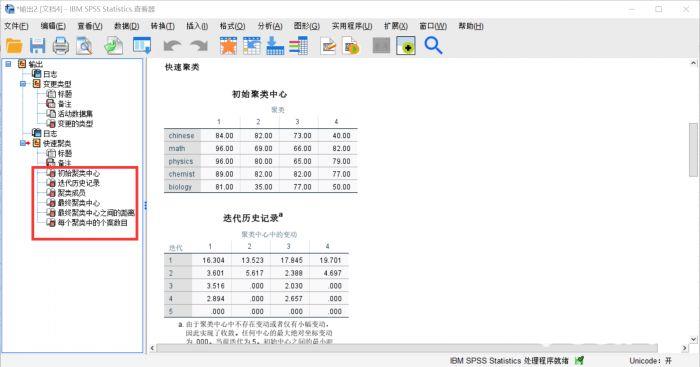) 图8:聚类结果
图8:聚类结果
从输出日志中可以看出,这些学生根据自己的单科成绩分为四类。SPSS输出了多个表格,包括初始聚类中心、迭代历史记录、聚类成员、最终聚类中心、最终聚类中心之间的距离和每个聚类中的案例数量,完整详细,可信度高。